Greets, hackfolk!
Like just about every year, last week I took the train up to Brussels for FOSDEM, the messy and wonderful carnival of free software and of those that make it. Mostly I go for the hallway track: to see old friends, catch up, scheme about future plans, and refill my hacker culture reserves.
I usually try to see if I can get a talk or two in, and this year was no exception. First on my mind was the recent release of Guile 3. This was the culmination of a 10-year plan of work and so obviously there are some things to say! But at the same time, I wanted to reflect back a bit and look at the past with a bit of distance.
So in the end, my one talk was two talks. Let's start with the first one. (I'm trying a new thing where I share my talks as blog posts. We'll see how this goes. I know the rendering can be a bit off relative to the slides, but hopefully it's good enough. If you prefer, you can just watch the video instead!)
Celebrating Guile 3
FOSDEM 2020, Brussels
Andy Wingo | wingo@igalia.com
wingolog.org | @andywingo
So yeah let's celebrate! I co-maintain the Guile implementation of Scheme. It's a programming language. Guile 3, in summary, is just Guile, but faster. We added a simple just-in-time compiler as well as a bunch of ahead-of-time optimizations. The result is that it runs faster -- sometimes by a lot!
![]()
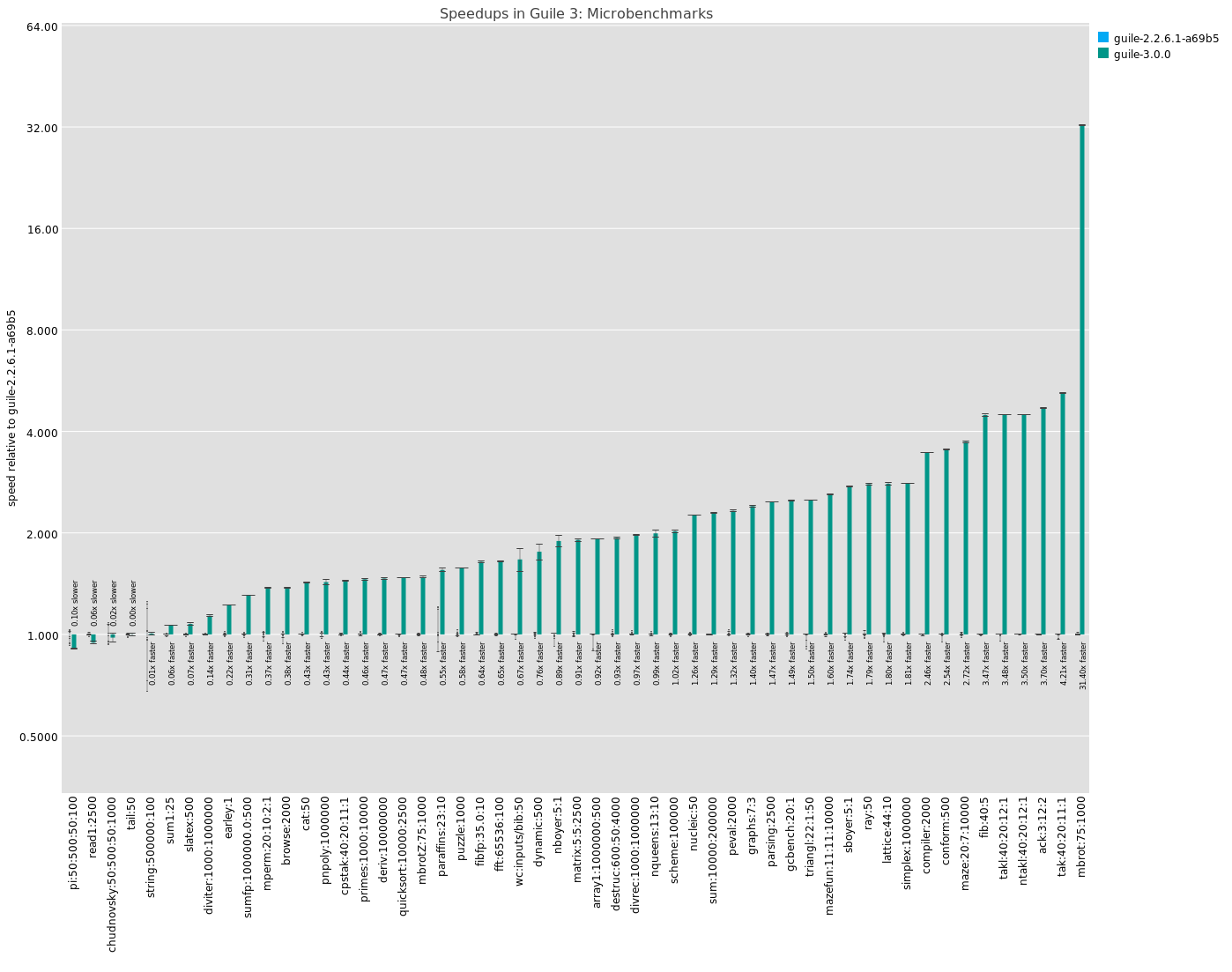
In the image above you can see Guile 3's performance on a number of microbenchmarks, relative to Guile 2.2, sorted by speedup. The baseline is 1.0x as fast. You can see that besides the first couple microbenchmarks where things are a bit inconclusive (click for full-size image), everything gets faster. Most are at least 2x as fast, and one benchmark is even 32x as fast. (Note the logarithmic scale on the Y axis.)
I only took a look at microbenchmarks at the end of the Guile 3 series; before that, I was mostly going by instinct. It's a relief to find out that in this case, my instincts did align with improvement.
mini-benchmark: eval
(primitive-eval’(let fib ((n 30))
(if (< n 2)
n
(+ (fib (- n 1)) (fib (- n 2))))))
Guile 1.8: primitive-eval written in C
Guile 2.0+: primitive-eval in Scheme
Taking a look at a more medium-sized benchmark, let's compute the 30th fibonacci number, but using the interpreter instead of compiling the procedure. In Guile 2.0 and up, the interpreter (primitive-eval) is implemented in Scheme, so it's a good test of an important small Scheme program.
Before 2.0, though, primitive-eval was actually implemented in C. This had a number of disadvantages, notably that it prevented tail calls between interpreted and compiled code. When we switched to a Scheme implementation of primitive-eval, we knew we would have a performance hit, but we thought that we would gain it back eventually as the compiler got better.
As you can see, it took a while before the compiler and run-time improved to the point that primitive-eval in Scheme reached the speed of its old hand-tuned C implementation, but for Guile 3, we finally got there. Note again the logarithmic scale on the Y axis.
macro-benchmark: guix
guix build libreoffice ghc-pandoc guix \
–dry-run --derivation
7% faster
guix system build config.scm \
–dry-run --derivation
10% faster
Finally, taking a real-world benchmark, the Guix package manager is implemented entirely in Scheme. All ten thousand packages are defined in Scheme, the building scripts are in Scheme, the initial RAM disk is in Scheme -- you get the idea. Guile performance in Guix can have an important effect on user experience. As you can see, Guile 3 lowered elapsed time for some operations by around 10 percent or so. Of course there's a lot of I/O going on in addition to computation, so Guile running twice as fast will rarely make Guix run twice as fast (Amdahl's law and all that).
So, when I was thinking about words that describe Guile, the word "spry" came to mind.
But actually when I went to look up the meaning of "spry", Collins Dictionary says that it especially applies to the agèd. At first I was a bit offended, but I knew in my heart that the dictionary was right.
Lessons Learned from Guile, the Ancient & Spry
FOSDEM 2020, Brussels
Andy Wingo | wingo@igalia.com
wingolog.org | @andywingo
That leads me into my second talk.
guile is ancient
2010: Rust
2009: Go
2007: Clojure
1995: Ruby
1995: PHP
1995: JavaScript
1993: Guile (33 years before 3.0!)
It's common for a new project to be lively, but Guile is definitely not new. People have been born, raised, and earned doctorates in programming languages in the time that Guile has been around.
built from ancient parts
1991: Python
1990: Haskell
1990: SCM
1989: Bash
1988: Tcl
1988: SIOD
Guile didn't appear out of nothing, though. It was hacked up from the pieces of another Scheme implementation called SCM, which itself was initially based on Scheme in One Defun (SIOD), back before the Berlin Wall fell.
written in an ancient language
1987: Perl
1984: C++
1975: Scheme
1972: C
1958: Lisp
1958: Algol
1954: Fortran
1958: Lisp
1930s: λ-calculus (34 years ago!)
But it goes back further! The Scheme language, of which Guile is an implementation, dates from 1975, before I was born; and you can, if you choose, trace the lines back to the lambda calculus, created in mid-30s as a notation for computation. I suppose at this point I should say mid-2030s, to disambiguate.
The point is, Guile is old! Statistically, most software projects from olden times are now dead. How has Guile managed to survive and (sometimes) thrive? Surely there must be some lesson or other that can be learned here.
ancient & spry
Men make their own history, but they do not make it as they please; they do not make it under self-selected circumstances, but under circumstances existing already, given and transmitted from the past.
The tradition of all dead generations weighs like a nightmare on the brains of the living. [...]
Eighteenth Brumaire of Louis Bonaparte, Marx, 1852
I am no philospher of history, but I know that there are some ways of looking at the past that do not help me understand things. One is the arrow of enlightened progress, in which events exist in a causal chain, each producing the next. It doesn't help me understand the atmosphere, tensions, and possibilities inherent at any particular point. I find the "progress" theory of history to be an extreme form of selection bias.
Much more helpful to me is the Hegelian notion of dialectics: that at an given point in time there are various tensions at work. In our field, an example could be memory safety versus systems programming. These tensions create an environment that favors actions that lead towards resolution of the tensions. It doesn't mean that there's only one way to resolve the tensions, and it's not an automatic process -- people still have to do things. But the tendency is to ratchet history forward to a new set of tensions.
The history of a project, to me, is then a process of dialectic tensions and resolutions. If the project survives, as Guile has, then it should teach us something about the way this process works in practice.
ancient & spry
Languages evolve; how to remain minimal?
Dialectic opposites
world and guile
stable and active
...
Lessons learned from inside Hegel’s motor of history
One dialectic is the tension between the world's problems and what tools Guile offers to understand and solve them. In 1993, the web didn't really exist. In 2033, if Guile doesn't run well in a web browser, probably it will be dead. But this process operates very slowly, for an old project; Guile isn't built on CORBA or something ephemeral like that, so we don't have very much data here.
The tension between being a stable base for others to build on, and in being a dynamic project that improves and changes, is a key tension that this talk investigates.
In the specific context of Guile, and for the audience of the FOSDEM minimal languages devroom, we should recognize that for a software project, age and minimalism don't necessarily go together. Software gets features over time and becomes bigger. What does it mean for a minimal language to evolve?
hill-climbing is insufficient
![]()
Ex: Guile 1.8; Extend vs Embed
One key lesson that I have learned is that the strategy of making only incremental improvements is a recipe for death, in the long term. The natural result is that you reach what you perceive to be the most optimal state of your project. Any change can only make it worse, so you stop moving.
This is what happened to Guile around version 1.8: we had taken the paradigm of the interpreter as language implementation strategy as far as it could go. There were only around 150 commits to Guile in 2007. We were stuck.
users stay unless pushed away
Inertial factor: interface
Source (API)
Binary (ABI)
Embedding (API)
CLI
...
Ex: Python 3; local-eval; R6RS syntax; set!, set-car!
So how do we make change, in such a circumstance? You could start a new project, but then you wouldn't have any users. It would be nice to change and keep your users. Fortunately, it turns out that users don't really go away; yes, they trickle out if you don't do anything, but unless you change in an incompatible way, they stay with you, out of inertia.
Inertia is good and bad. It does conflict with minimalism as a principle; if you were to design Scheme in 2020, you would not include mutable variables or even mutable pairs. But they are still with us because if we removed them, we'd break too many users.
Users can even make you add back things that you had removed. In Guile 2.0, we removed the capability to evaluate an expression at run-time within the lexical environment of an expression, as we didn't know how to implement this outside an interpreter. It turns out this was so important to users that we had to add local-eval back to Guile, later in the 2.0 series. (Fortunately we were able to do it in a way that layered on lower-level facilities; this approach reconciled me to the solution.)
you can’t keep all users
What users say: don’t change or remove existing behavior
But: sometimes losing users is OK. Hard to know when, though
No change at all == death
Ex: psyntax; BDW-GC mark & finalize; compile-time; Unicode / locales
Unfortunately, the need to change means that sometimes you will lose users. It's either a dead project, or losing users.
In Guile 1.8, for example, the macro expander ran lazily: it would only expand code the first time it ran it. This was good for start-up time, because not all code is evaluated in the course of a simple script. Lazy expansion allowed us to start doing important work sooner. However, this approach caused immense pain to people that wanted "proper" Scheme macros that preserved lexical scoping; the state of the art was to eagerly expand an entire file. So we switched, and at the same time added a notion of compile-time. This compromise kept good start-up time while allowing fancy macros.
But eager expansion was a change. Users that relied on side effects from macro expansion would see them at compile-time instead of run-time. Users of old "defmacros" that could previously splice in live Scheme closures as literals in expanded source could no longer do that. I think it was the right choice but it did lose some users. In fact I just got another bug report related to this 10-year-old change last week.
every interface is a cost
Guile binary ABI: libguile.so; compiled Scheme files
Make compatibility easier: minimize interface
Ex: scm_sym_unquote, GOOPS, Go, Guix
So if you don't want to lose users, don't change any interface. The easiest way to do this is to minimize your interface surface. In Go, for example, they mostly haven't had dynamic-linking problems because that's not a thing they do: all code is statically linked into binaries. Similarly, Guix doesn't define a stable API, because all of its code is maintained in one "monorepo" that can develop in lock-step.
You always have some interfaces, though. For example Guix can't change its command-line interface from one day to the next, for example, because users would complain. But it's been surprising to me the extent to which Guile has interfaces that I didn't consider. Recently for example in the 3.0 release, we unexported some symbols by mistake. Users complained, so we're putting them back in now.
parallel installs for the win
Highly effective pattern for change
libguile-2.0.so
libguile-3.0.so
https://ometer.com/parallel.html
Changed ABI is new ABI; it should have a new name
Ex: make-struct/no-tail, GUILE_PKG([2.2]), libtool
So how does one do incompatible change? If "don't" isn't a sufficient answer, then parallel installs is a good strategy. For example in Guile, users don't have to upgrade to 3.0 until they are ready. Guile 2.2 happily installs in parallel with Guile 3.0.
As another small example, there's a function in Guile called make-struct (old doc link), whose first argument is the number of "tail" slots, followed by initializers for all slots (normal and "tail"). This tail feature is weird and I would like to remove it. Unfortunately I can't just remove the argument, so I had to make a new function, make-struct/no-tail, which exists in parallel with the old version that I can't break.
deprecation facilitates migration
__attribute__ ((__deprecated__))
(issue-deprecation-warning
"(ice-9 mapping) is deprecated."" Use srfi-69 or rnrs hash tables instead.")
scm_c_issue_deprecation_warning
("Arbiters are deprecated. ""Use mutexes or atomic variables instead.");begin-deprecated, SCM_ENABLE_DEPRECATED
Fortunately there is a way to encourage users to migrate from old interfaces to new ones: deprecation. In Guile this applies to all of our interfaces (binary, source, etc). If a feature is marked as deprecated, we cause its use to issue a warning, ideally at compile-time when users responsible for the package can fix it. You can even add __attribute__((__deprecated__)) on C types!
the arch-pattern
Replace, Deprecate, Remove
All change is possible; question is only length of deprecation period
Applies to all interfaces
Guile deprecation period generally one stable series
Ex: scm_t_uint8; make-struct; Foreign objects; uniform vectors
Finally, you end up in a situation where you have replaced the old interface and issued deprecation warnings to help users migrate. The next step is to remove the old interface. If you don't do this, you are failing as a project maintainer -- your project becomes literally unmaintainable as it just grows and grows.
This strategy applies to all changes. The deprecation period may last a while, and it may be that the replacement you built doesn't serve the purpose. There is still a dialog with the users that needs to happen. As an example, I made a replacement for the "SMOB" facility in Guile that allows users to define new types, backed by C interfaces. This new "foreign object" facility might not actually be good enough to replace SMOBs; since I haven't formally deprecatd SMOBs, I don't know yet because users are still using the old thing!
change produces a new stable point
Stability within series: only additions
Corollary: dependencies must be at least as stable as you!
Ex: libtool; unistring; gnulib
In my experience, the old management dictum that "the only constant is change" does not describe software. Guile changes, then it becomes stable for a while. You need an unstable series escape hill-climbing, then once you found your new hill, you start climbing again in the stable series.
Once you reach your stable point, the projects you rely on need to exhibit the same degree of stability that you envision for your project. You can't build a web site that you expect to maintain for 10 years on technology that fundamentally changes every 6 months. But stable dependencies isn't something you can ensure technically; rather it relies on social norms of who makes the software you use.
who can crank the motor of history?
All libraries define languages
Allow user to evolve the language
Guile 1.8 perf created tension
Compiler removed pressure on C ABI
Empowered users need less from you
A dialectic process does not progress on its own: it requires actions. As a project maintainer, some of my actions are because I want to do them. Others are because users want me to do them. The user-driven actions are generally a burden and as a lazy maintainer, I want to minimize them.
Here I think Guile has to a large degree escaped some of the pressures that weigh on other languages, for example Python. Because Scheme allows users to define language features that exist on par with "built-in" features, users don't need my approval or intervention to add (say) new syntax to the language they work in. Furthermore, their work can still compose with the work of others, even if the others don't buy in to their language extensions.
Still, Guile 1.8 did have a dynamic whereby the relatively poor performance of having to run all code through primitive-eval meant that users were pushed towards writing extensions in C. This in turn pushed Guile to expose all of its guts for access from C, which obviously has led to an overbloated C API and ABI. Happily the work on the Scheme compiler has mostly relieved this pressure, and we may therefore be able to trim the size of the C API and ABI over time.
contributions and risk
From maintenance point of view, all interface is legacy
Guile: Sometimes OK to accept user modules when they are more stable than Guile
In-tree users keep you honest
Ex: SSAX, fibers, SRFI
It can be a good strategy to "sediment" solutions to common use cases into Guile itself. This can improve the minimalism of an entire ecosystem of code. The maintenance burden has to be minimal, however; Guile has sometimes adopted experimental code into its repository, and without active maintenance, it soon becomes stale relative to what users and the module maintainers expect.
I would note an interesting effect: pieces of code that were adopted into Guile become a snapshot of the coding style at that time. It's useful to have some in-tree users because it gives you a better idea about how a project is seen from the outside, from a code perspective.
sticky bits
Memory management is an ongoing thorn
Local maximum: Boehm-Demers-Weiser conservative collector
How to get to precise, generational GC?
Not just Guile; e.g. CPython __del__
There are some points that resist change. The stickiest of these is the representation of heap-allocated Scheme objects in C. Guile currently uses a garbage collector that "automatically" finds all live Scheme values on the C stack and in registers. It was the right choice at the time, given our maintenance budget. But to get the next bump in performance, we need to switch to a generational garbage collector. It's hard to do that without a lot of pain to C users, essentially because the C language is too weak to express the patterns that we would need. I don't know how to proceed.
I would note, though, that memory management is a kind of cross-cutting interface, and that it's not just Guile that's having problems changing; I understand PyPy has had a lot of problems regarding changes on when Python destructors get called due to its switch from reference counting to a proper GC.
future
We are here: stability
And then?
Remove myself from “holding the crank”
So where are we going? Nowhere, for the moment; or rather, up the hill. We just released Guile 3.0, so let's just appreciate that for the time being.
But as far as next steps in language evolution, I think in the short term they are essentially to further enable change while further sedimenting good practices into Guile. On the change side, we need parallel installability for entire languages. Racket did a great job facilitating this with #lang and we should just adopt that.
As for sedimentation, we should step back and if any common Guile use patterns built by our users should be include core Guile, and widen our gaze to Racket also. It will take some effort both on a technical perspective but also on a social/emotional consensus about how much change is good and how bold versus conservative to be: putting the dialog into dialectic.
dialectic, boogie woogie woogie
https://gnu.org/s/guile
https://wingolog.org/
#guile on freenode
@andywingo
wingo@igalia.com
Happy hacking!
Hey that was the talk! Hope you enjoyed the writeup. Again, video and slides available on the FOSDEM web site. Happy hacking!
















































 This arguably depicts my efforts to clean up the cruft and pick up the missing pieces.
This arguably depicts my efforts to clean up the cruft and pick up the missing pieces.

 What the project probably looked like from an outsider’s perspective. Actually applies to many open-source projects out there.
What the project probably looked like from an outsider’s perspective. Actually applies to many open-source projects out there.
 ;
; “That sounds like a reference to the Rebuild of Evangelion”, you say?
“That sounds like a reference to the Rebuild of Evangelion”, you say? “Burning the Brushwood” (1893), by Eero Järnefelt
“Burning the Brushwood” (1893), by Eero Järnefelt


