We recently had a Fedora AMA where one of the questions asked is why GNOME is the default desktop for Fedora Workstation. In the AMA we answered why GNOME had been chosen for Fedora Workstation, but we didn’t challenge the underlying assumption built into the way the question was asked, and the answer to that assumption is that it isn’t the default. What I mean with this is that Fedora Workstation isn’t a box of parts, where you have default options that can be replaced, its a carefully procured and assembled operating system aimed at developers, sysadmins and makers in general. If you replace one or more parts of it, then it stops being Fedora Workstation and starts being ‘build your own operating system OS’. There is nothing wrong with wanting to or finding it interesting to build your own operating systems, I think a lot of us initially got into Linux due to enjoying doing that. And the Fedora project provides a lot of great infrastructure for people who want to themselves or through teaming up with others build their own operating systems, which is why Fedora has so many spins and variants available.
The Fedora Workstation project is something we made using those tools and it has been tested and developed as an integrated whole, not as a collection of interchangeable components. The Fedora Workstation project might of course over time replace certain parts with other parts over time, like how we are migrating from X.org to Wayland. But at some point we are going to drop standalone X.org support and only support X applications through XWayland. But that is not the same as if each of our users individually did the same. And while it might be technically possible for a skilled users to still get things moved back onto X for some time after we make the formal deprecation, the fact is that you would no longer be using ‘Fedora Workstation’. You be using a homebrew OS that contains parts taken from Fedora Workstation.
So why am I making this distinction? To be crystal clear, it is not to hate on you for wanting to assemble your own OS, in fact we love having anyone with that passion as part of the Fedora community. I would of course love for you to share our vision and join the Fedora Workstation effort, but the same is true for all the other spins and variant communities we have within the Fedora community too. No the reason is that we have a very specific goal of creating a stable and well working experience for our users with Fedora Workstation and one of the ways we achieve this is by having a tightly integrated operating system that we test and develop as a whole. Because that is the operating system we as the Fedora Workstation project want to make. We believe that doing anything else creates an impossible QA matrix, because if you tell people that ‘hey, any part of this OS is replaceable and should still work’ you have essentially created a testing matrix for yourself of infinite size. And while as software engineers I am sure many of us find experiments like ‘wonder if I can get Fedora Workstation running on a BSD kernel’ or ‘I wonder if I can make it work if I replace glibc with Bionic‘ fun and interesting, I am equally sure we all also realize what once we do that we are in self support territory and that Fedora Workstation or any other OS you use as your starting point can’t not be blamed if your system stops working very well. And replacing such a core thing as the desktop is no different to those other examples.
Having been in the game of trying to provide a high quality desktop experience both commercially in the form of RHEL Workstation and through our community efforts around Fedora Workstation I have seen and experienced first hand the problems that the mindset of interchangeable desktop creates. For instance before we switched to the Fedora Workstation branding and it was all just ‘Fedora’ I experienced reviewers complaining about missing features, features had actually spent serious effort implementing, because the reviewer decided to review a different spin of Fedora than the GNOME one. Other cases I remember are of customers trying to fix a problem by switching desktops, only to discover that while the initial issue they wanted fix got resolved by the switch they now got a new batch of issues that was equally problematic for them. And we where left trying to figure out if we should try to fix the original problem, the new ones or maybe the problems reported by users of a third desktop option. We also have had cases of users who just like the reviewer mentioned earlier, assumed something was broken or missing because they where using a different desktop than the one where the feature was added. And at the same time trying to add every feature everywhere would dilute our limited development resources so much that it made us move slow and not have the resources to focus on getting ready for major changes in the hardware landscape for instance.
So for RHEL we now only offer GNOME as the desktop and the same is true in Fedora Workstation, and that is not because we don’t understand that people enjoy experimenting with other desktops, but because it allows us to work with our customers and users and hardware partners on fixing the issues they have with our operating system, because it is a clearly defined entity, and adding the features they need going forward and properly support the hardware they are using, as opposed to spreading ourselves to thin that we just run around putting on band-aids for the problems reported.
And in the longer run I actually believe this approach benefits those of you who want to build your own OS to, or use an OS built by another team around a different set of technologies, because while the improvements might come in a bit later for you, the work we now have the ability to undertake due to having a clear focus, like our work on adding HiDPI support, getting Wayland ready for desktop use or enabling Thunderbolt support in Linux, makes it a lot easier for these other projects to eventually add support for these things too.
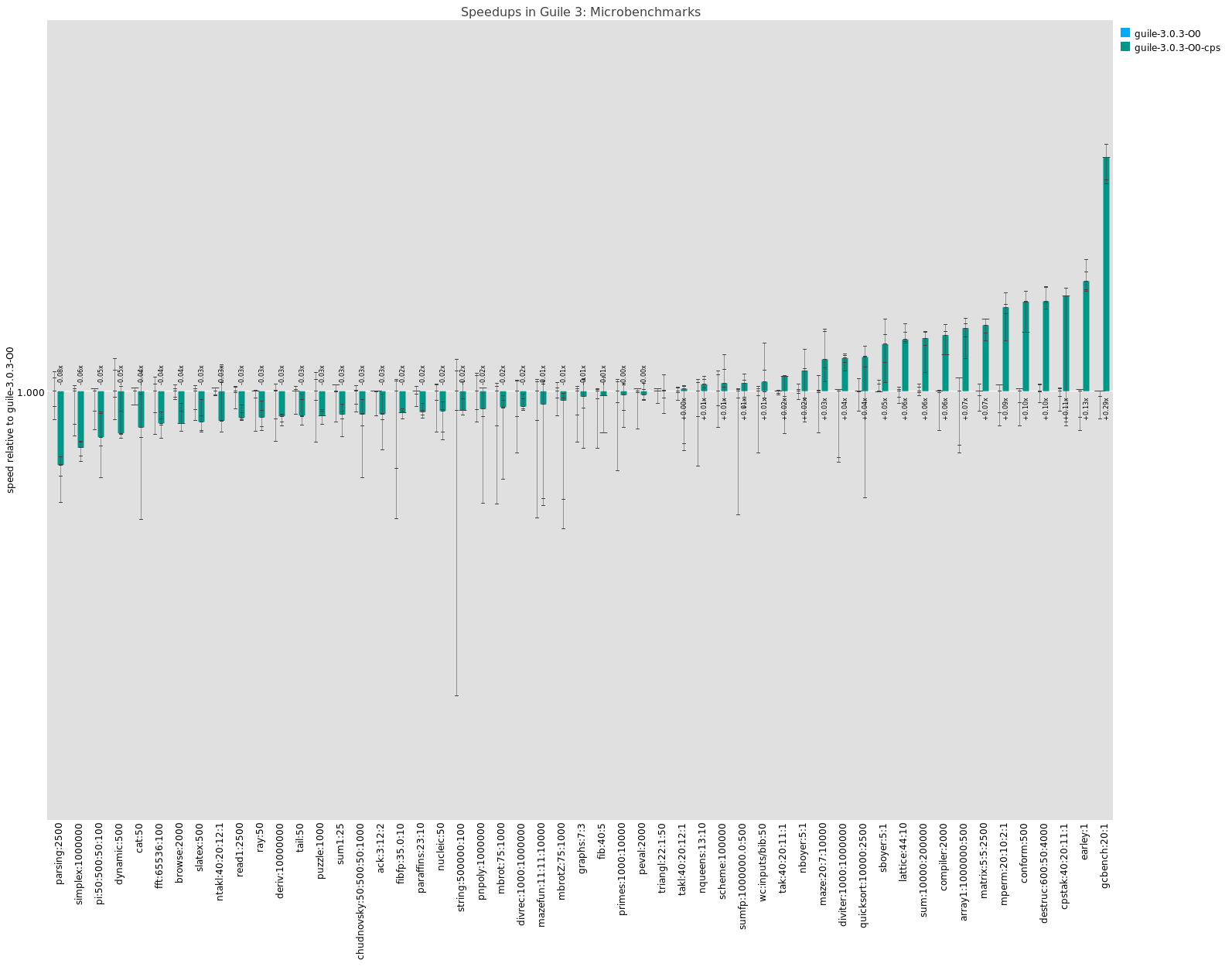
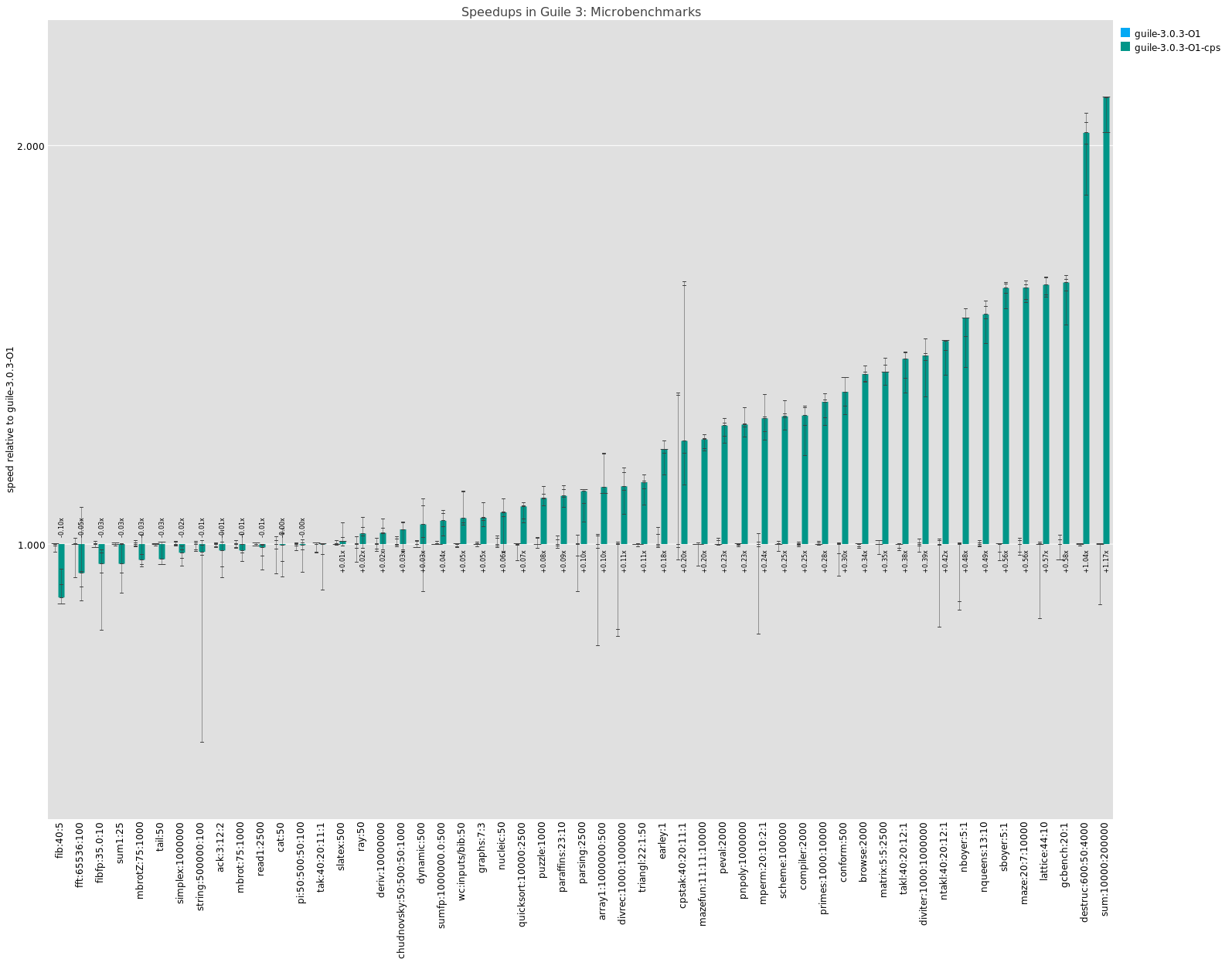
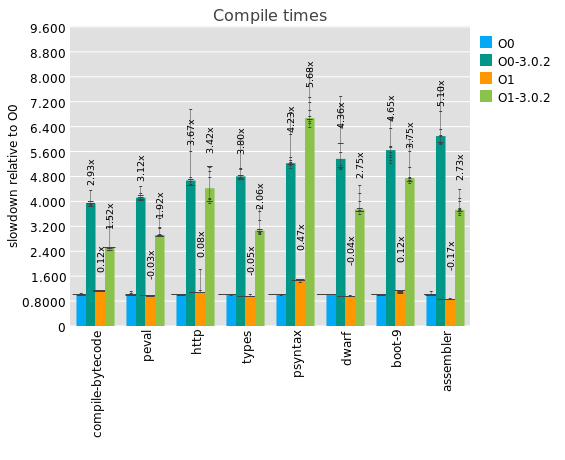
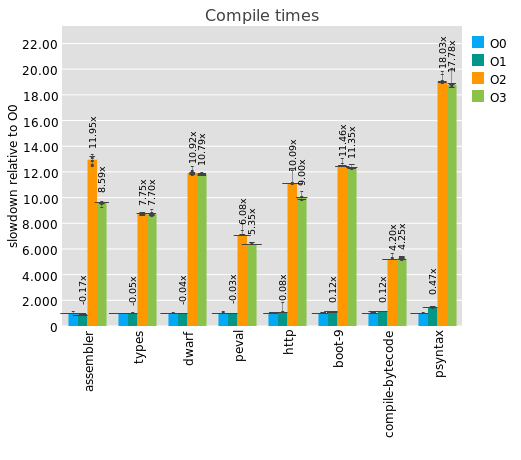

 At this point, it seems to be quite robust and safe to use, so I need you to test it like maniacs.
At this point, it seems to be quite robust and safe to use, so I need you to test it like maniacs.



