We are very proud to be announcing today the 0.4 release of Getting Things GNOME (“GTG”), codenamed “You Are (Not) Done”. This much-awaited release is a major overhaul that brings together many updates and enhancements, including new features, a modernized user interface and updated underlying technology.
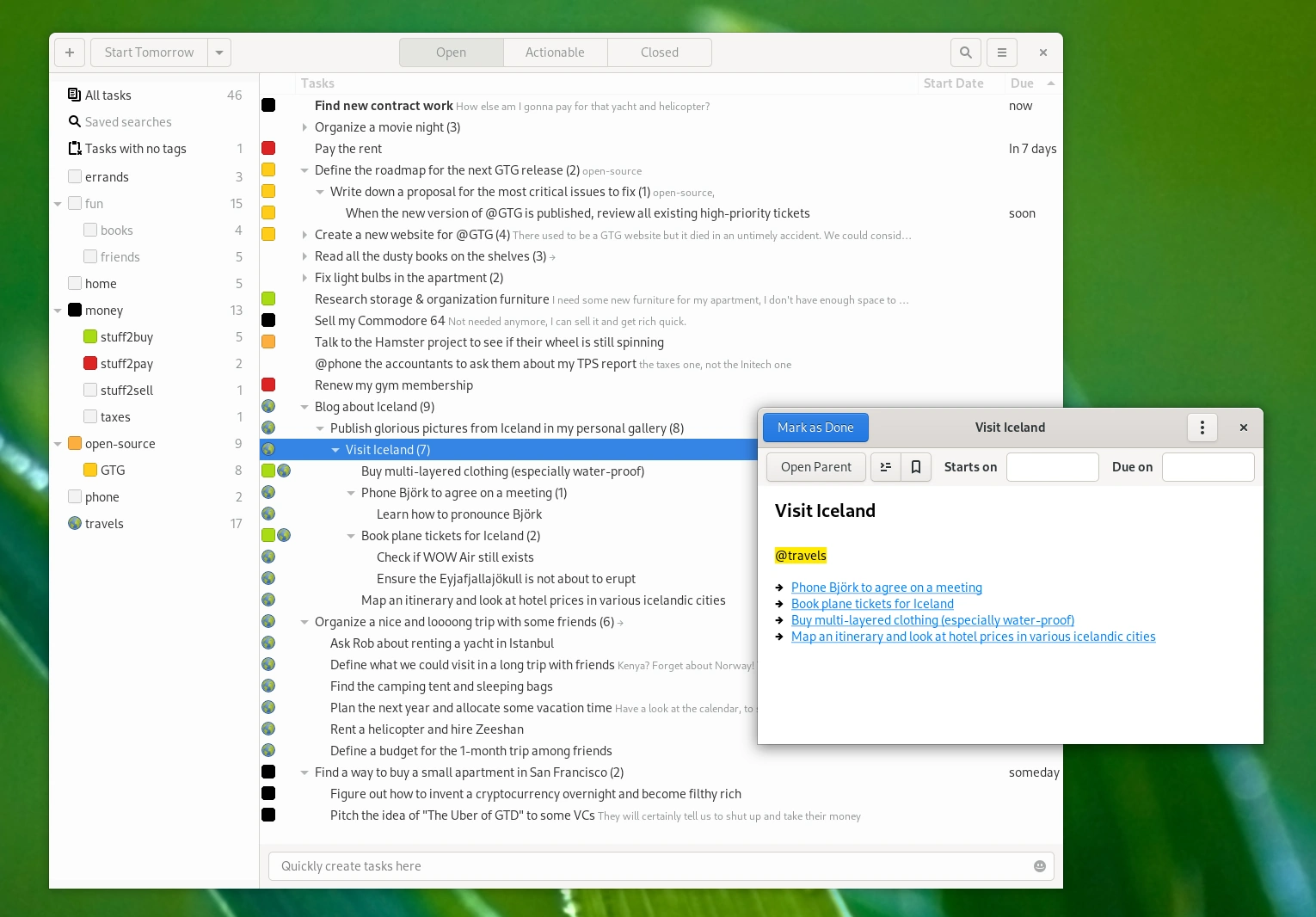 Screenshot of GTG 0.4
Screenshot of GTG 0.4
Beyond what is featured in these summarized release notes below, GTG itself has undergone over 630 changes affecting over 500 files, and received hundreds of bug fixes, as can be seen on here and here.
We are thankful to all of our supporters and contributors, past and present, who made GTG 0.4 possible. Check out the “About” dialog for a list of contributors for this release.
A summary of GTG’s development history and a high-level explanation of its renaissance can be seen in this teaser video:
A demonstration video provides a tour of GTG’s current features:
A few words about the significance of this release
As a result of the new lean & agile project direction and contributor workflow we have formalized, this release—the first in over 6.5 years—constitutes a significant milestone in the revival of this community-driven project.
This milestone represents a very significant opportunity to breathe new life into the project, which is why I made sure to completely overhaul the “contributor experience”, clarifying and simplifying the process for new contributors to make an impact.
I would highly encourage everybody to participate towards the next release. You can contribute all sorts of improvements to this project, be it bug fixes or new features, adopting one of the previous plugins, doing translation and localization work, working on documentation, or spreading the word. Your involvement is what makes this project a success.
— Jeff (yours truly)
“When I switched from Linux to macOS a few years ago, I never found a todo app that was as good as GTG, so I started to try every new shiny (and expensive) thing. I used Evernote, Todoist, Things and many others. Nothing came close. I spent the next 6 years trying every new productivity gadget in order to find the perfect combo.
— Lionel Dricot, original author of GTG (quote edited with permission)
In 2019, Jeff decided to take over GTG and bring it back from the grave. It’s a strange feeling to see your own creation continuing in the hands of others. Living to see your software being developed by others is quite an accomplishment. Jeff’s dedication demonstrated that, with GTG, we created a tool which can become an essential part of chaos warrior’s productivity system. A tool which is useful without being trendy, even years after it was designed. A tool that people still want to use. A tool that they can adapt and modernise. This is something incredible that can only happen with Open Source.”
It has been over seven years since the 0.3rd impact. This might very well be the Fourth Impact. Shinji, get in the f%?%$ing build bot!
— Gendo Ikari
Release notes

Technology Upgrades
GTG and libLarch have been fully ported to Python 3, GTK 3, and GObject introspection (PyGI).
User Interface and Frontend Improvements
General UI overhaul
The user interface has been updated to follow the current GNOME Human Interface Guidelines (HIG), style (see GH GTG PR #219 and GH GTG PR #235 for context) and design patterns:
- Client-side window decorations using the GTK HeaderBar widget. Along with the removal of the menu bars, this saves a significant amount of space and allows for more content to be displayed on screen.
- The Preferences dialog was redesigned, and its contents cleaned up to remove obsolete settings (see GH GTG PR #227).
- All windows are properly parented (set as transient) with the main window, so that they can be handled better by window managers.
- Symbolic icons are available throughout the UI.
- Improvements to padding and borders are visible throughout the application.
Main window (“Task Browser”)
- The menu bar has been replaced by a menu button. Non-contextual actions (for example: toggle Sidebar, Plugins, Preferences, Help, and About) have been moved to the main menu button.
- Searching is now handled through a dedicated Search Bar that can be toggled on and off with the mouse, or the Ctrl+F keyboard shortcut.
- The “Workview” mode has been renamed to the “Actionable” view. “Open”, “Actionable”, and “Closed” tasks view modes are available (see GH GTG PR #235).
- An issue with sorting tasks by title in the Task Browser has been fixed: sorting is no longer case-sensitive, and now ignores tag marker characters (GH GTG issue #375).
- Start/Due/Closed task dates now display as properly translated in the Task Browser (GH GTG issue #357)
- In the Task Browser’s right-click context menus, more start/due dates choices are available, including common upcoming dates and a custom date picker (GH GTG issue #244).
Task Editor
- The Calendar date picker pop-up widgets have been improved (see GH GTG PR #230).
- The Task Editor now attempts to place newly created windows in a more logical way (GH GTG issue #287).
- The title (first line of a task) has been changed to a neutral black header style, so that it doesn’t look like a hyperlink.
New Features
- You can now open (or create) a task’s parent task (GH GTG issue #138).
- You can now select multiple closed tasks and perform bulk actions on them (GH GTG issue #344).
- It is now possible to rename or delete tags by right-clicking on them in the Task Browser.
- You can automatically generate and assign tag colors. (LP GTG issue #644993)
- The Quick Add entry now supports emojis
![🤩]()
- The Task Editor now provides a searchable “tag picker” widget.
- The “Task Reaper” allows deleting old closed tasks for increased performance. Previously available as a plugin, it is now a built-in feature available in the Preferences dialog (GH GTG issue #222).
- The Quick Deferral (previously, the “Do it Tomorrow” plugin) is now a built-in feature. It is now possible to defer multiple tasks at once to common upcoming days or to a custom date (GH GTG issue #244).
- In the unlikely case where GTG might encounter a problem opening your data file, it will automatically attempt recovery from a previous backup snapshot and let you know about it (LP GTG issue #971651)

Backend and Code Quality improvements
- Updates were made to overall code quality (GH GTG issue #237) to reduce barriers to contribution:
- The code has been ported to use GtkApplication, resulting in simpler and more robust UI code overall.
- GtkBuilder/Glade “.ui” files have been regrouped into one location.
- Reorganization of various .py files for consistency.
- The debugging/logging system has been simplified.
- Various improvements to the test suite.
- The codebase is mostly PEP8-compliant. We have also relaxed the PEP8 max line length convention to 100 characters for readability, because this is not the nineties anymore.
- Support is available for Tox, for testing automation within virtualenvs (see GH GTG PR #239).
- The application’s translatable strings have been reviewed and harmonized, to ensure the entire application is translatable (see GH GTG PR #346).
- Application CSS has been moved to its own file (see GH GTG PR #229).
- Outdated plugins and synchronization services have been removed (GH GTG issue #222).
- GTG now provides an “AppData” (FreeDesktop AppStream metadata) file to properly present itself in distro-agnostic software-centers.
- The Meson build system is now supported (see GH GTG PR #315).
- The development version’s launch script now allows running the application with various languages/locales, using the LANG environment variable for example.
- Appdata and desktop files are named based on the chosen Meson profile (see GH GTG PR #349).
- Depending on the Meson profile, the HeaderBar style changes dynamically to indicate when the app is run in a dev environment, such as GNOME Builder (GH GTG issue #341).
Documentation Updates
- The user manual has been rewritten, reorganized, and updated with new images (GH GTG issue #243). It is also now available as an online publication.
- The contributor documentation has been rewritten to make it easier for developers to get involved and to clarify project contribution guidelines (GH GTG issue #200). Namely, updates were made to the README.md file to clarify the set-up process for the development version, as well as numerous new guides and documentation for contributors in the docs/contributors/ folder.
Infrastructure and other notable updates
- The entire GTG GNOME wiki site has been updated (GH GTG issue #200), broken links have been fixed, references to the old website have been removed.
- We have migrated from LaunchPad to GitHub (and eventually GitLab), so references to LaunchPad have been removed.
- We now have social media accounts on Mastodon and Twitter (GH GTG issue #294).
- Flatpak packages on Flathub are going to be our official direct upstream-to-user software distribution mechanism (GH GTG issue #233).
Notice
In order to bring this release out of the door, some plugins have been disabled and are awaiting adoption by new contributors to test and maintain them. Please contribute to maintain your favorite plugin. Likewise, we had to remove the DBus module (and would welcome help to bring it back into a better shape, for those who want to control the app via DBus).
Getting and installing GTG 0.4
We hope to have our flatpak package ready in time for this announcement, or shortly afterwards. See the install page for details.
Spreading this announcement
We have made some social postings on Twitter, on Mastodon and on LinkedIn that you can re-share/retweet/boost. Please feel free to link to this announcement on forums and blogs as well!
The post Rebuild of EvanGTGelion: Getting Things GNOME 0.4 released! appeared first on The Open Sourcerer.